
生成AIは、ビジネスのあらゆる場面で活用が期待される一方、時として事実に基づかない情報を生成する「ハルシネーション」や、学習データが古いために最新情報に対応できないといった課題を抱えています。
この課題を解決する技術として、今、大きな注目を集めているのが「RAG(Retrieval-Augmented Generation)」です。
本記事では、RAGが単なる技術解説に留まらず、企業の競争力をいかに高めるかという「ビジネス戦略を立案するストラテジスト」の視点から、その仕組み、メリット、そして具体的な導入ステップまでを徹底的に解説します。
この記事を読めば、RAGが自社の「知識資産」を競争力を高めるための戦略的な一手として、自社でどう活用すべきか、具体的なイメージが湧きます。
-
- RAGの基本的な仕組みと、生成AIの精度を向上させる理由
- RAGとファインチューニングの具体的な違いと、自社に適した手法の選び方
- 企業がRAGを導入し、ビジネスで活用するための具体的なステップと事例
1.RAG(Retrieval-Augmented Generation)とは何か?~生成AIの「弱点」を克服する新技術~

RAG(Retrieval-Augmented Generation)は、直訳すると「検索拡張生成」となります。
これは、生成AIが回答を生成する際に、外部の信頼できる情報源から関連データを「検索(Retrieval)」し、その情報でAIの知識を「拡張(Augmented)」して、より精度の高い回答を「生成(Generation)」する技術的アプローチです。
この概念は、2020年にFacebook AI Research(当時)の研究者らによって発表された論文で初めて提案されました。
出典:Cornell University Computer Science > Computation and Language
生成AIが抱える「ハルシネーション」と「知識の鮮度」という2つの課題
生成AI、特に大規模言語モデル(LLM)は非常に強力ですが、ビジネスで利用するには看過できない2つの課題が存在します。
- ハルシネーション(Hallucination): 大規模言語モデル(LLM)が学習データに存在しない、事実に基づかない情報を、もっともらしく生成してしまう現象です。これは、企業の意思決定や顧客対応で誤った情報を提供してしまう重大なリスクに繋がります。
- 知識の鮮度:大規模言語モデル(LLM)は、ある特定の時点までのデータで学習されています。そのため、学習データに含まれていない最新の出来事や、社内の新しい規定といった情報には答えることができません。
RAGは、これらの課題を解決するために考案されました。
RAGは「外部の信頼できる知識」をAIに与える仕組み
RAGは、大規模言語モデル(LLM)が元々持っている広範な知識に頼るだけでなく、回答を生成するその都度、外部の最新かつ信頼性の高いナレッジベース(企業の社内マニュアル、製品カタログ、データベースなど)を参照します。
これにより、AIは「知ったかぶり」をすることなく、根拠に基づいた正確な回答を生成できるようになるのです。
2.RAGの仕組みを図解でわかりやすく解説
RAGの仕組みは、大きく3つのステップに分けられます。
ここでは、ユーザーが「A製品の最新の保守費用は?」と質問した場合を例に、そのプロセスを解説します。
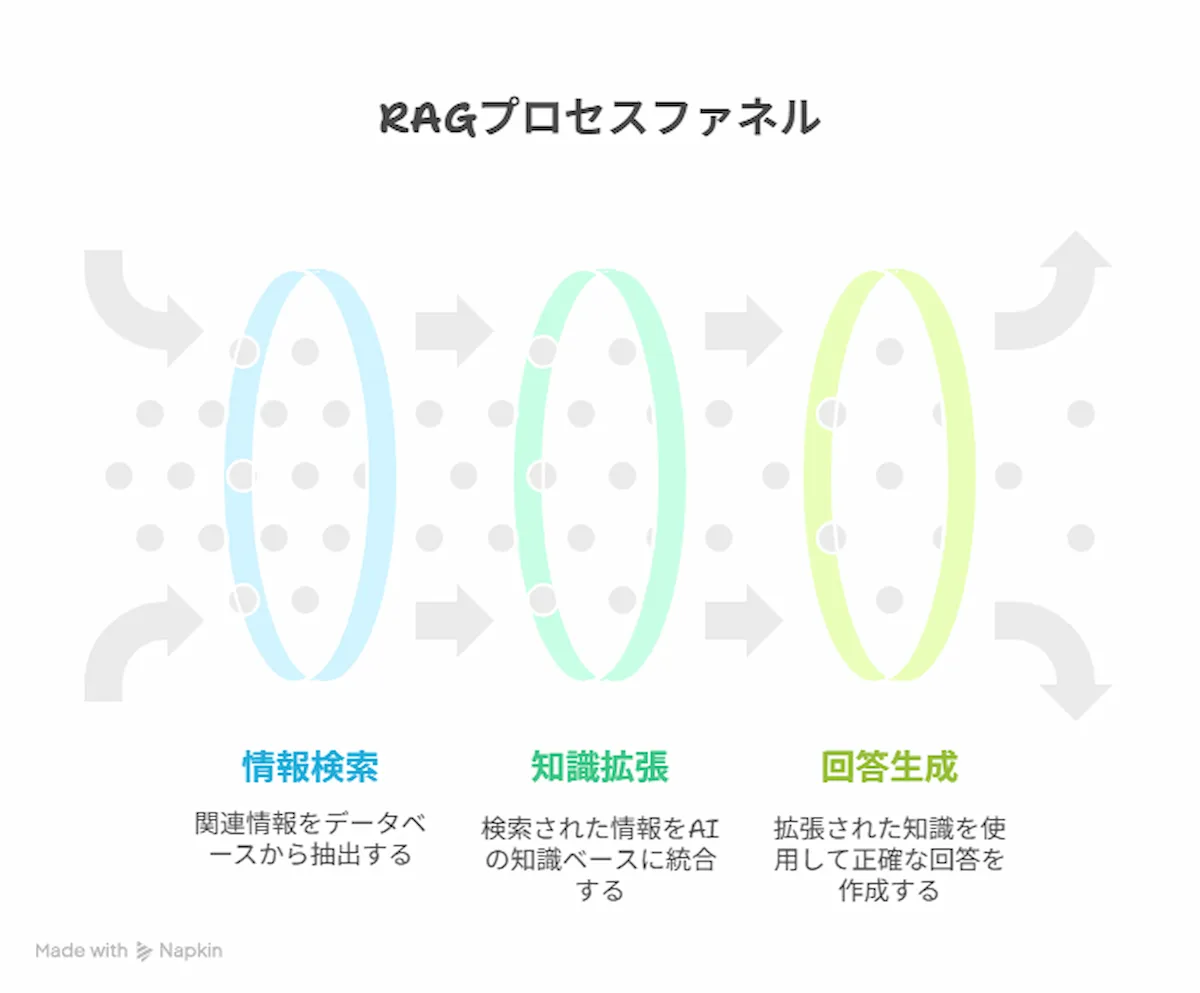
ステップ1:ユーザーの質問に関連する情報をデータベースから検索(Retrieval)
まず、システムはユーザーの質問「A製品の最新の保守費用は?」を受け取ると、大規模言語モデル(LLM)に直接問い合わせる前に、あらかじめ用意された企業のナレッジベース(料金表データベースや製品マニュアルなど)を検索します。
このとき、質問の意図を理解し、最も関連性の高い情報(例:「A製品保守費用改定のお知らせ(2025年版)」)を見つけ出します。
ステップ2:検索結果をプロンプトに含めてAIに提供(Augmented)
次に、ステップ1で見つけ出した関連情報(「A製品の最新の保守費用は年額XX円です」というデータ)を、元の質問と一緒に大規模言語モデル(LLM)への指示文(プロンプト)に組み込みます。
これにより、プロンプトは「『A製品の最新の保守費用は年額XX円です』という情報を参考にして、『A製品の最新の保守費用は?』という質問に答えてください」といった具体的なものに拡張されます。
ステップ3:AIが最新かつ正確な情報に基づいて回答を生成(Generation)
最後に、拡張されたプロンプトを受け取った大規模言語モデル(LLM)は、参照情報に基づいて回答を生成します。
これにより、大規模言語モデル(LLM)は自身の古い知識ではなく、プロンプトに含まれた最新の正確な情報を使って「A製品の最新の保守費用は、年額XX円です」と回答することができます。
3.RAGを導入する3つのメリット

企業がRAGを導入することで、以下のような大きなメリットが期待できます。
メリット1:ハルシネーションを抑制し、回答の信頼性を向上させる
RAGの最大のメリットは、回答が信頼できる外部データソースに基づいているため、ハルシネーションを大幅に抑制できることです。
これにより、AIの回答に「なぜそうなるのか」という根拠が生まれ、ユーザーは安心してその情報を利用できます。
メリット2:社内文書など、独自のデータをAIに活用できる
一般的な大規模言語モデル(LLM)が学習していない、企業の機密情報や専門知識、社内規定といった独自のデータをAIに活用させることが可能です。
これにより、汎用的なAIを、自社のビジネスに特化した強力なツールへとカスタマイズできます。
メリット3:ファインチューニングに比べ、低コストかつ迅速に導入できる
AIを特定のタスクに適応させるもう一つの手法「ファインチューニング」は、モデル全体を再学習させるため、大量のデータと高い計算コスト、専門知識が必要です。
一方、RAGは既存の大規模言語モデル(LLM)はそのままに、外部データベースと連携させる仕組みなので、比較的低コストかつ迅速に導入を進めることが可能です。
4.RAGの2つのデメリットと導入前に考慮すべき課題

多くのメリットがある一方、RAGの導入には注意すべき点も存在します。
課題1:検索システムの精度が、回答品質を左右する
RAGの性能は、ステップ1の「検索」の精度に大きく依存します。ユーザーの質問に対して、的確な情報をナレッジベースから見つけ出せなければ、大規模言語モデル(LLM)も質の高い回答を生成することはできません。
「Garbage In, Garbage Out(ゴミを入れれば、ゴミしか出てこない)」の原則はここでも当てはまり、データ品質の重要性はAI導入における最大の障害の一つと最大の障害の一つと見なされることもあります。
課題2:データの前処理や管理にコストがかかる
参照するナレッジベースを常に最新かつ正確な状態に保つための、継続的なデータ管理(クレンジング、更新、整理)が必要です。
この運用・保守には、人的リソースやコストがかかることを理解しておく必要があります。
課題3:情報セキュリティリスクがある
参照するナレッジベースのアクセス権管理に不備があると、AIが閲覧権限のない機密情報に意図せずアクセスし、情報漏洩を引き起こす重大なリスクとなります。
厳格なアクセス制御に加え、従業員向けの利用ガイドライン策定といった組織的なガバナンス体制の構築が必要です。
5.【意思決定フレームワーク】RAGとファインチューニングの違いと使い分け
RAGとファインチューニングは、どちらもAIを特定の目的に合わせてカスタマイズする手法ですが、その特性は大きく異なります。
どちらか一方が優れているというわけではなく、目的に応じて適切に使い分けることが重要です。
ここでは、自社に最適な手法を選択するための「意思決定フレームワーク」を提示します。
| 比較項目 | RAG(検索拡張生成) | ファインチューニング |
|---|---|---|
| 目的 | 事実に基づいた回答生成、知識のアップデート | 特定の文体、トーン、スタイルへの適応 |
| 仕組み | 外部データベースを「検索・参照」する | モデル自体を「再学習」させる |
| コスト | 比較的低い | 高い(計算リソース、教師データ準備) |
| 導入期間 | 比較的短い | 長い |
| 知識の更新 | 容易(データベースを更新するだけ) | 困難(再学習が必要) |
| ハルシネーション | 抑制しやすい | 抑制しにくい場合がある |
RAGが適しているケース:最新情報や社内ナレッジの活用
- 例:社内規定に関する問い合わせに答えるAIチャットボット、最新の在庫状況を反映した製品説明の生成、顧客サポート履歴を基にしたFAQ作成。
- 判断基準:「事実の正確性」や「情報の鮮度」が最重要視される場合に適しています。
ファインチューニングが適しているケース:特定の文体や専門用語への適応
- 例:特定のブランドイメージに合わせたマーケティングコピーの生成、法律や医療分野の専門用語を多用する文書の要約、特定のキャラクターとしての対話AI。
- 判断基準:AIの「振る舞い」や「応答スタイル」を根本的に変えたい場合に適しています。
また、両者を組み合わせ、ファインチューニングでAIの基礎能力を調整し、RAGで最新情報に対応させるハイブリッドなアプローチも有効です。
6.RAGの具体的なビジネス活用事例
RAGは、既に様々なビジネスシーンでその価値を発揮し始めています。
活用事例1:高精度な社内向けAIチャットボットの構築

社内の就業規則、経費精算マニュアル、ITサポート情報などをナレッジベースとしてRAGと連携させることで、従業員からの様々な質問に24時間365日、正確に自動応答するAIチャットボットを構築できます。
これにより、管理部門の問い合わせ対応業務を大幅に削減できます。
活用事例2:最新の市場データに基づいたレポート作成の自動化

日々更新される市場調査データや売上データをRAGの参照先とすることで、最新の状況を反映した定型レポートを自動で生成できます。これにより、担当者はデータ収集・整理作業から解放され、より戦略的な分析業務に集中できます。
活用事例3:顧客からの問い合わせに対する回答生成の支援

コンタクトセンターにおいて、顧客との対話中にRAGが関連する過去の問い合わせ事例やFAQをオペレーターに提示することで、応対品質の向上と時間短縮を実現します。
これは、RAGのA(Augmented)が意味する、AIによる能力拡張の好例です。
7.企業がRAG導入を成功させるための3つのステップ
RAGの導入は技術プロジェクトではなく、事業戦略の一環です。成功確率を高めるためには、以下の3つのステップで段階的に進めることが推奨されます。
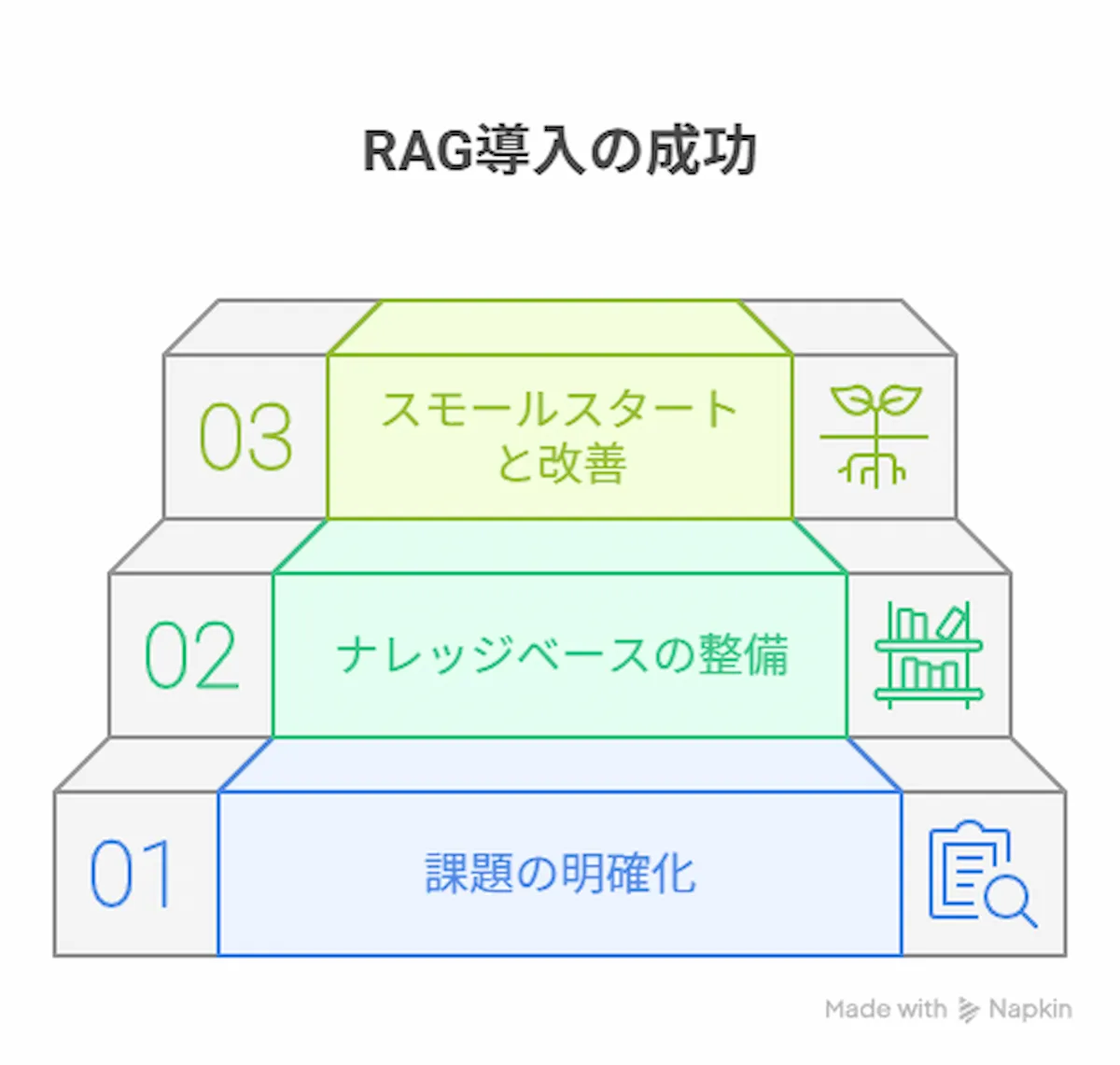
ステップ1:課題の明確化とPoC(概念実証)の計画
まず、「AIを使おう」という技術先行の発想ではなく、「どのビジネス課題を解決したいのか」という課題特定から始めます。
例えば、「営業部門の製品知識のばらつきをなくしたい」「経理部門への定型的な問い合わせを30%削減したい」といった具体的な目標を設定します。
その上で、その仮説を検証するための小規模な実証実験(PoC)を計画します。PoCは「早く、安く失敗する」ことで学びを得るための重要なプロセスです。
ステップ2:参照させるナレッジベースの整備と品質管理
RAGの成否を分けるのが、参照させる情報の品質です。
社内に散在するマニュアルや文書、データを整理・集約し、重複の削除や表記ゆれの統一といったデータクレンジングを行います。
このデータの前処理・クレンジング作業は、プロジェクト全体の8割の労力を占めることもある重要な工程です。
ステップ3:スモールスタートと継続的な改善
PoCで有効性が確認できたら、特定の部門やチームといった小規模な範囲で実際の運用を開始します(スモールスタート)。
最初から完璧を目指すのではなく、現場の利用者からフィードバックを収集し、検索精度の向上やナレッジベースの拡充といった改善を継続的に行っていくことが成功の鍵です。
この循環的な改善プロセス(MLOps)と強固なガバナンスが、AIの価値を持続させるために不可欠となります。
8.RAGは企業の「知識資産」を競争力に変える戦略的一手
本記事では、生成AIの精度と信頼性を飛躍的に向上させる技術「RAG」について、その仕組みから具体的な導入ステップまでを解説しました。
RAGは、単にAIの弱点を補うための技術ではありません。
企業内に眠る独自のデータや専門知識という「隠れた資産」を、AIの強力な思考力と安全に結びつけ、新たな競争優位性を生み出すための「戦略的コンポーネント」です。
AIの導入はもはや選択ではなく、必須の時代。
しかし、成功の秘訣は、AI導入自体を目的にするのではなく、「どのビジネス課題を解決するのか」という明確な目的を持つことです。
RAGの価値を理解し、それを自社の問題解決に応用する視点を持つことが、AI時代を乗りこなすための出発点となるでしょう。



